What's VPA and How It Works
Vertical Pod Autoscaler (VPA) is Kubernetes' implementation of vertical autoscaling.
VPA is designed to automatically adjust the CPU and memory resource requests and limits for containers within pods. VPA aims to solve one of the most challenging aspects of Kubernetes resource management: accurately setting resource requests and limits. VPA continuously monitors the resource usage of your pods and makes recommendations or automatic adjustments to ensure your containers have the right amount of resources.
Using VPA in a correct way offers multiple benefits that directly impact resource and cost efficiency. By dynamically adjusting resource allocations based on actual usage, it ensures efficient resource utilization and reduces overprovisioning, a common pitfall in manual resource management. This leads to an improved performance-to-cost ratio, as more workloads can run on the same infrastructure. The automatic nature of these adjustments saves valuable time and effort that would otherwise be spent on manual tuning, allowing teams to focus on more strategic tasks. As applications' resource needs evolve over time, vertical autoscaling adapts accordingly, maintaining optimal resource allocation without human intervention. This adaptability, combined with more efficient resource use, contributes to better cost predictability and an overall reduction in cloud spending. Ultimately, vertical autoscaling creates a more cost-effective Kubernetes environment that automatically balances performance needs with resource efficiency, optimizing cloud spending while maintaining system reliability and performance.
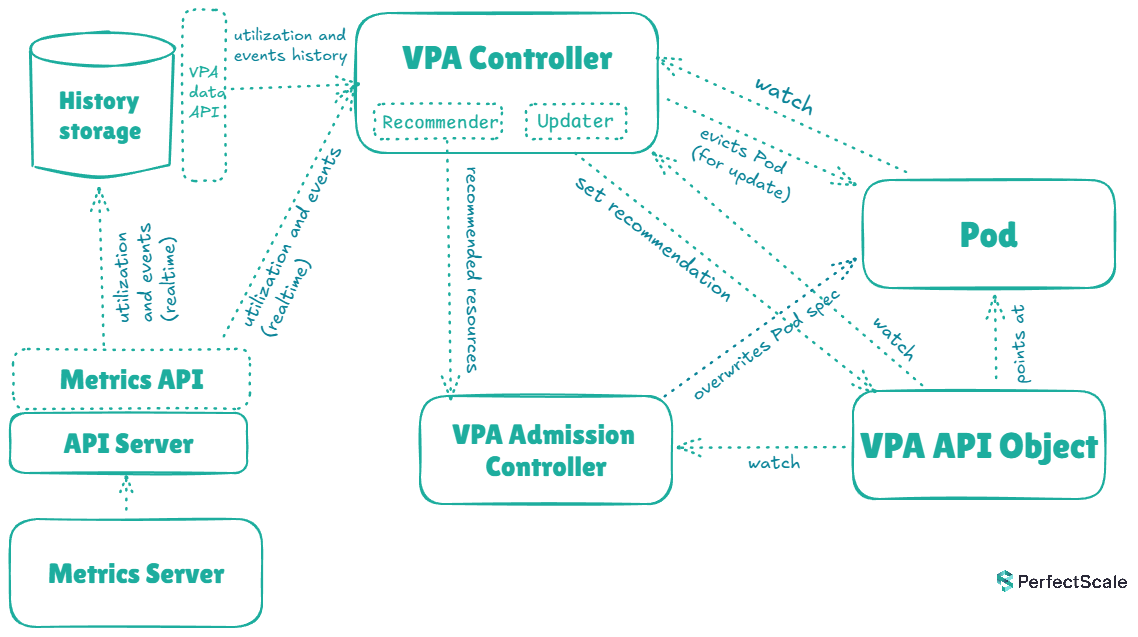
VPA consists of 3 main components (each running as a separate deployment):
-
the VPA Recommender
-
the VPA Updater
-
the VPA Admission Controller
These components work together to collect data, analyze resource usage, generate recommendations, and apply changes to pod specifications.
The VPA Recommender is responsible for analyzing resource usage patterns and generating recommendations for CPU and memory settings. It continuously monitors the resource consumption of containers using metrics provided by the Kubernetes Metrics Server.
The VPA Updater is the component responsible for applying the recommendations generated by the Recommender. When operating in "Auto" mode, the Updater will delete pods that need updating and create new ones with the adjusted resource settings. It's important to note that this process can be affected by Pod Disruption Budget (PDB) settings, stalling the update process. In the future - when the InPlacePodVerticalScaling feature goes out of Alpha - pod updates should be possible without deletion
The VPA Admission Controller intercepts pod creation requests and modifies the resource requirements according to the VPA recommendations. This ensures that even newly created pods start with adjusted resource settings, improving overall cluster efficiency from the outset.
One of the key features of VPA is its ability to operate in different modes, providing flexibility to cluster administrators. In "Off" mode, VPA generates recommendations but does not apply them automatically, allowing for manual review and application. The "Initial" mode applies recommendations only when new pods are created, which can be useful in scenarios where pod restarts are not desirable. The "Auto" mode, as mentioned earlier, actively applies recommendations to both new and existing pods.
VPA incorporates several safety measures to prevent potential issues that could arise from frequent resource adjustments. It respects pod disruption budgets to ensure service availability, implements hysteresis in its decision-making process to avoid oscillations, and can be configured with min/max boundaries to prevent extreme resource allocations.
VPA Limitations
1. VPA focuses on pod resource usage without considering the available node resources. This can lead to recommendations that, while optimal for the pod, might not be feasible given the cluster's actual capacity, resulting in pods that can't be scheduled.
2. Java applications with their complex memory management through the JVM present a unique challenge. VPA may struggle to accurately gauge the true resource needs of these applications, leading to suboptimal scaling decisions. Also, it can't identify memory leaks and JVM CPU init bursts.
3. To implement resource changes, VPA needs to recreate pods. This process, while necessary for applying new configurations, can cause brief periods of unavailability for the affected workloads, which might be problematic for applications requiring high availability.
4. While VPA works well in smaller environments, its performance in large, production-scale clusters with hundreds or thousands of nodes and pods remains a question mark. This uncertainty can be a significant concern for enterprises considering VPA for their large-scale deployments.
5. By focusing primarily on CPU and memory, VPA overlooks other crucial resources like network bandwidth and disk I/O. In I/O-intensive applications, this oversight can lead to performance bottlenecks that VPA won't address or may even exacerbate.
6. For stateful applications, the pod restart process during VPA updates can be more disruptive and may require additional considerations, such as proper handling of data consistency and state management during restarts.
7. The VPA operates based on historical resource usage data without considering workload revisions or updates. In modern, fast-paced environments where new versions of applications are frequently deployed, this can lead to suboptimal resource recommendations. VPA may apply the same resource adjustments to a newly deployed version that has different resource requirements than its predecessor. This limitation can result in unnecessary pod mutations and
inappropriate resource allocations for new revisions, especially in environments with daily or frequent deployments.
Optimizing VPA:
Let's dive into strategies for optimizing VPA’s use to maximize cost savings and efficiency:
1. Start with Proper Resource Benchmarking:
Before implementing VPA, conduct thorough resource benchmarking of your applications. This will give you a baseline understanding of resource usage patterns and help you set initial requests more accurately preventing over-provisioning from the start, immediately reducing costs. You can use tools like Prometheus and Grafana for this process.
2. Use the Right Update Mode:
Start with "Initial" mode, then move to "Auto" gradually. This approach allows you to monitor cost impacts and fine-tune before fully automating, preventing unexpected spikes in resource allocation and costs.
3. Set Appropriate Resource Bounds:
Use the `minAllowed` and `maxAllowed` fields in your VPA configuration to set lower and upper bounds for resource requests. This prevents over-allocation while still allowing for necessary scaling, directly impacting cost efficiency.
VPA configuration with resource bounds:
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: my-app-vpa
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: my-app
updatePolicy:
updateMode: "Auto"
resourcePolicy:
containerPolicies:
- containerName: '\*'
minAllowed:
cpu: 100m
memory: 128Mi
maxAllowed:
cpu: 1
memory: 1Gi
4. Use Pod Disruption Budgets:
Use Pod Disruption Budgets (PDBs) in conjunction with VPA, but configure them with cost in mind. Allow for more disruption during off-peak hours when it's cheaper to reallocate resources:
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: cost-aware-pdb
spec:
maxUnavailable: 50%
selector:
matchLabels:
app: my-app
6. Use VPA Recommender Histograms:
Regularly analyze VPA histogram data to identify cost-saving opportunities. Look for patterns where resources are under-utilized and adjust your VPA configuration accordingly.
7. Implement Custom Resource Policies:
Use custom resource policies to fine-tune how VPA handles specific containers or sets of containers. This allows for more granular control over resource management. By tailoring resource policies to specific workload requirements, you can optimize resource allocation and reduce costs by preventing over-provisioning of resources for containers that don't need them.
8. Fine-Tuning with Multiple Recommenders:
One advanced technique for optimizing VPA is to leverage multiple recommenders. While Kubernetes' default VPA implementation uses a single recommender, it's possible to implement and integrate custom recommenders to achieve more nuanced resource allocation, leading to improved cost efficiency and optimal performance.
Why Use Multiple Recommenders?
Utilizing multiple recommenders in your resource optimization strategy offers several advantages for cost and resource efficiency. By implementing specialized algorithms tailored to different workload types, you can achieve more accurate and context-aware resource recommendations, preventing over-provisioning and reducing costs. This approach allows you to incorporate business-specific logic, such as cost thresholds or performance SLAs, directly into the recommendation process. Custom recommenders enable the integration of external data sources, providing valuable insights from anticipated traffic patterns or scheduled batch jobs. Using recommenders that operate on various time scales allows for both short-term adjustments and long-term capacity planning. This multi-faceted approach can lead to more efficient resource utilization, reducing costs while maintaining the application performance. Also, custom recommenders can be designed to consider factors like node affinity, pod disruption budgets, or specific application behaviors that may not be captured by default recommenders. By using multiple recommenders, you create a more robust and adaptive system.
Implementing Multiple Recommenders:
This approach involves creating custom recommenders using the Kubernetes Metrics API and VPA APIs, implemented as separate microservices within your cluster. A crucial component in this setup is the Recommendation Aggregator, which combines inputs from various recommenders and makes final decisions based on predefined rules or machine learning models. To integrate this system with the VPA, you'll need to modify the VPA controller to use your custom aggregator instead of the default recommender, which requires changes to the VPA source code and rebuilding its components.
Let’s take an example of an e-commerce application, you might have one recommender analyzing historical sales data to predict resource needs for upcoming events, another monitoring real-time user traffic for immediate adjustments, and a third incorporating cost data to ensure recommendations stay within budget constraints. The aggregator would then synthesize these inputs to provide a balanced recommendation that optimizes both performance and cost.
It's important to thoroughly test this custom setup in a non-production environment before deployment. This approach can lead to more accurate, context-aware resource optimization, making improvements in both cost efficiency and application performance. You can have a look here for more information.
6. Integrating VPA with Cluster Autoscaler or Karpenter:
To achieve true cost optimization, it's crucial to integrate VPA with cluster-level autoscaling solutions like Cluster Autoscaler or Karpenter. This integration ensures that not only are your pods right-sized, but your overall cluster resources are also optimized.
Why is this integration important?
VPA focuses on optimizing resources at the pod level, but it doesn't directly influence the number or size of nodes in your cluster. Without proper cluster-level autoscaling, you might end up with right-sized pods but underutilized or overloaded nodes, which doesn't translate to real cost savings.
Integrating with Cluster Autoscaler:
Integrating VPA with Cluster Autoscaler requires an understanding of their interplay and configuration. Cluster Autoscaler responds to pod scheduling needs by adding or removing nodes, which can be indirectly triggered by VPA's resource adjustments. To optimize this integration, ensure your Cluster Autoscaler is configured with appropriate min/max node counts and scale-down delays to prevent unnecessary scaling actions that could lead to increased costs. Implement Kubernetes Pod Priority and Preemption to ensure critical pods are scheduled even during cluster scaling events. Closely monitor the interaction between VPA and Cluster Autoscaler, looking for patterns where VPA adjustments consistently trigger scaling events, and adjust configurations to minimize unnecessary infrastructure costs. This integrated approach will lead to a more cost-effective Kubernetes environment with optimized resource utilization.
Integrating with Karpenter:
Karpenter is a more flexible and efficient cluster autoscaler for Kubernetes. Integrating VPA with Karpenter can lead to even more optimized resource utilization and cost savings:
1. Karpenter's Fast Node Provisioning:
Karpenter can quickly provision nodes that precisely match pod requirements, reducing overprovisioning and associated costs. This works well with VPA's dynamic resource adjustments to ensure optimal resource allocation.
2. Use Karpenter Provisioners:
Configure Karpenter Provisioners to align with your VPA strategies and cost objectives. Create provisioners optimized for specific workload types that VPA is managing, ensuring the most cost-effective instance types are used.
3. Implement Consolidation:
Take advantage of Karpenter's consolidation feature, which can move pods to optimize node utilization. This complements VPA's pod-level optimizations, further reducing infrastructure costs by eliminating underutilized nodes.
4. Custom Resource Management:
Utilize Karpenter's support for custom resources in conjunction with VPA to manage specialized workloads more effectively, ensuring that expensive custom resources are allocated efficiently.
To effectively integrate VPA and cluster autoscaling, adopt a gradual implementation approach, starting with separate implementations and progressively integrating them for non-critical workloads. Set conservative thresholds initially to prevent rapid fluctuations, adjusting as system stability and cost benefits are confirmed. Implement monitoring using tools like Prometheus and Grafana to track both pod-level and node-level metrics. Utilize Kubernetes simulation tools to model the impact of VPA and autoscaling decisions before production deployment. Design your system to handle potential failure scenarios, incorporating manual override procedures and fallback configurations to maintain system resilience and cost efficiency.
